Deep Mental Models for Solidity ABI Encoding: Part 1


For Solidity developers, ABI Encoding/Decoding is THE topic to master.
It's one of those topics that separates you from the rest - makes you a 10x solidity dev.
On the other hand, it's a topic that could be very difficult to grasp. It's one of the most complex sections of the Solidity official documentation. ( trust me, i tried "deciphering" it.) ,My aim with this article series is to simplify ABI encoding for every Solidity developer.
Read Part-0 to understand why learn ABI Encoding/Decoding in Solidity 👇

Now, let's get started.
Quick Refresher
The Application Binary Interface (ABI) in EVM defines how data structures and function calls are encoded and decoded for communication between contracts and external actors (like web3 clients or off-chain code).
It acts as the translation layer between high-level Solidity code and low-level EVM operations.
ABI encoding is strictly defined, deterministic, and consistent across all EVM-compatible chains, which is what enables Ethereum tools like ethers.js, web3.js, Foundry, and Remix to interact with smart contracts predictably, without having to understand your Solidity source code at all.
If you’ve ever called a function like this:
myContract.call(abi.encodeWithSignature("transfer(address,uint256)", recipient, amount));
Or decoded event data like this:
abi.decode(data, (uint256, address));
You’ve already touched ABI encoding.
You’ve seen the hexadecimal blobs that result from encoding a function call — something like:
0xa9059cbb0000000000000000000000005B38Da6a701c568545dCfcB03FcB875f56beddC40000000000000000000000000000000000000000000000000000000000000064
That's an ABI-encoded function call, and it’s what the EVM understands when executing your code. This article is precisely about how we got this encoded hexadecimal value.
My aim with this ABI Encoding series is to:
- provide the prerequisites for grasping ABI encoding
- deeply explain how ABI encoding actually works
- provide solid mental models to encode any given function & arguments
I'll walk you through the precise structure of ABI-encoded data and help you master the fundamental laws of encoding that govern how any input, irrespective of its complexity, is transformed into raw bytes that the EVM can execute.
By the end of this guide, you’ll be able to look at any function signature and arguments, and manually reconstruct the exact ABI-encoded calldata, byte for byte — and do the reverse through decoding.
But first, some prerequisites you must understand.
Primer for Noobs
a. MSB and LSB
- MSB: Most Significant Byte (MSB) is the byte that contributes the largest to the overall value
- LSB: Least Significant Byte (LSB) is the byte that contributes the smallest
For example, consider the decimal number 2,984:
- Changing the digit 4 to 5 increases the number by 1, but
- Changing the digit 2 to 3 increases the number by 1,000.
This concept applies to bytes and bits as well.
Let’s take the integer 0x12345678 ( 305419896 in decimal), which takes 4 bytes (32 bits):
| Byte Position | Big-Endian | Little-Endian |
|---|---|---|
| Byte 0 | 0x12 (most significant) |
0x78 (least significant) |
| Byte 1 | 0x34 |
0x56 |
| Byte 2 | 0x56 |
0x34 |
| Byte 3 | 0x78 (least significant) |
0x12 (most significant) |
b. Endianness: Big-Endian vs Little-Endian
Endianness refers to how multi-byte values are laid out in memory:
- Big-endian means the most significant bytes come first
- Little-endian means the least significant bytes come first
For instance, imagine a uint32 with the decimal value 305419896. In hex, that's 0x12345678
Now, Big-endian encoding would store it like this:
Memory Layout (Big-endian): [12][34][56][78]So the MSB 0x12 comes first.
On the other hand, Little-endian encoding would store it like this:
Memory Layout (Little-endian):[78][56][34][12]Here, the LSB 0x78 comes first — everything is reversed.
c. Padding
In ABI encoding, padding means adding extra zero bytes to align a value to a 32-byte (256-bit) boundary.
In Solidity ABI, most values are encoded as 32 bytes (256 bits).
If your data is smaller (like a 1-byte boolean or a 20-byte address), it must be padded (usually with zeros) to become 32 bytes.
You will notice 2 types of padding:
- Left-padding is used for integers or addresses. ( for static types ):
- You place the actual value at the right end of a 32-byte word
- All remaining unused bytes on the left are filled with
0x00 - For instance, if we encode the number 1 - uint256(1)
0x0000000000000000000000000000000000000000000000000000000000000001
- Right-padding is used for bytes<M> (e.g. bytes3) and string/bytes
( for dynamic types)- You place the actual value at the left end of the block
- All remaining unused bytes on the right are filled with
0x00 - For instance, bytes("abc")
// "abc" in hex - 616263
0x6162630000000000000000000000000000000000000000000000000000000000
This is right-padded, and the data is left-aligned in the 32-byte block.
d. Static vs Dynamic Types
This brings us to a crucial distinction of types in Solidity ( this will come in handy more than you think )
There are two main types in Solidity:
- Static Type: A type whose size is fixed at compile time.
- Dynamic Type: A type whose size may vary at runtime.
Here is a quick table of the different types that fall into each category:
| Category | Examples |
|---|---|
| Static | uint256, bool, address, bytes32, uint[2], fixed-size tuples |
| Dynamic | string, bytes, uint[], address[], dynamic tuples |
It's important to determine the type because the ABI encoding mechanism, as well as padding, differs based on the type you are encoding.
e. Calldata
In Solidity, calldata is the read-only, non-modifiable input data passed to a function call. It includes everything that is sent from an external source (a wallet, script, or contract) to a function when invoking it.
From the perspective of ABI encoding, calldata is where the full ABI-encoded payload is stored.
This payload includes:
- A 4-byte function selector
- ABI-encoded arguments, padded and laid out as per ABI rules ( rules we will learn in next section )
Every time you call a contract function externally (whether from Remix, Ethers.js, or Foundry), the calldata is constructed using the ABI encoding rules and sent to the EVM for execution.
Here’s a simplified structure:
calldata = [function selector][arguments encoding]f. Function Selector
The function selector is the first 4 bytes of calldata. It uniquely identifies which function should be called on the contract.
Quick glance at how it works:
- Solidity computes the function selector by taking the first 4 bytes of the Keccak-256 hash of the function signature.
- The function signature is a string made up of the function name and the exact types of its parameters, without spaces.
For example:
function transfer(address to, uint256 amount)Its signature string is:
"transfer(address,uint256)"
// Its keccak256() hash would be: 0xa9059cbb2ab09eb219583f4a59a5d0623ade346d962bcd4e46b11da047c9049b
The first 4 bytes (a9059cbb) is the function selector, and it becomes the prefix of calldata.
Every ABI-encoded calldata must start with the correct function selector so that the EVM knows which function in the contract to dispatch to.
Now you have the basics and prerequisites needed to understand the inner workings of ABI encoding.
So let's start with the laws of encoding.
Fundamental Rules of ABI Encoding
For any given function and arguments:
- Create a tuple of all function arguments in a head-tail formation ( first all heads, then all tails )
- Encode all the HEADs
- Encode all the TAILs
- Combine all the encodings to get the final encoded value
Those are the fundamental laws, and they will never change.
Don't worry if you have no clue what it all means.
Allow me to define them and then explain with examples.
Bear with me.
Now, let’s define the terms first:
- Encoding
- Encoding means turning a high-level value (like a number, a string, or an array) into a fixed sequence of bytes that the EVM can understand and work with.
- In Solidity ABI encoding:
- All data is encoded in 32-byte (256-bit) chunks.
- Every value is transformed in a predictable way based on its type
- The goal is to create a binary representation that can be decoded back into the original value on-chain
You can think of encoding like translating from human-readable values to EVM-readable binary.
- What is HEAD
- Whenever we encode a given value ( or set of values ), there two parts in the final encoded result, head and tail.
- The head is the first part of the encoded value for each argument.
- It either contains the actual value (for fixed-size types), or points to where the value can be found (for dynamic types).
- Rules for Head Encoding:
- The encoding of the head depends on the type being encoded:
- For Static Types:
- The head holds the actual encoded value, padded to 32 bytes.
- These values live entirely within the head — there is no tail for static types.
- For Dynamic Types:
- The head does not contain the actual value.
- Instead, it holds a 32-byte offset, which tells the EVM where to find the tail — i.e., the actual data.
- What is TAIL
- The tail is the second part of the encoded value where the actual data of dynamic types lives.
- It comes after the head section and may vary in size depending on the argument values.
- Rules for Tail Encoding:
- For static types, the tail is always empty - NO TAILS.
- For dynamic types, it includes the actual data. The tail of a dynamic type of data includes 2 main things:
- a length prefix (how long is the string or array)
- the actual bytes, padded so everything aligns to 32-byte chunks.
These are the most fundamental set of rules for encoding any given set of values in EVM. And they will always hold true.
For example:
a. encoding of dynamic types will require an understanding of offsets. ( we will cover this later when we get to it )
b. encoding of dynamic nested arrays or arrays inside structs, etc will have new terms of relative-offset.
We will cover such examples in the next parts.
But again, fundamentals will always hold.
Understanding HEAD-TAIL Visually
To understand the concept of HEAD-TAIL visually, let's take 2 very simple examples:
function staticType with 2 static type arguments
function staticType(uint256 a, uint256 b) public pure returns (bytes memory){
return msg.data;
}
function dynamicType with 1 dynamic type argument
function dynamicType(string memory s) public pure returns(bytes memory ){
return msg.data;
}When you execute these functions, they will return the calldata, which is the function-selector along with the ABI-encoded values of the arguments passed.
Let's take a quick look at each of their encoded calldata:
Calldata for staticType function:
Function-Selector: 74b4a150
------------
[000]: 0000000000000000000000000000000000000000000000000000000000000001
[020]: 0000000000000000000000000000000000000000000000000000000000000002
Its visual representation can be seen as:
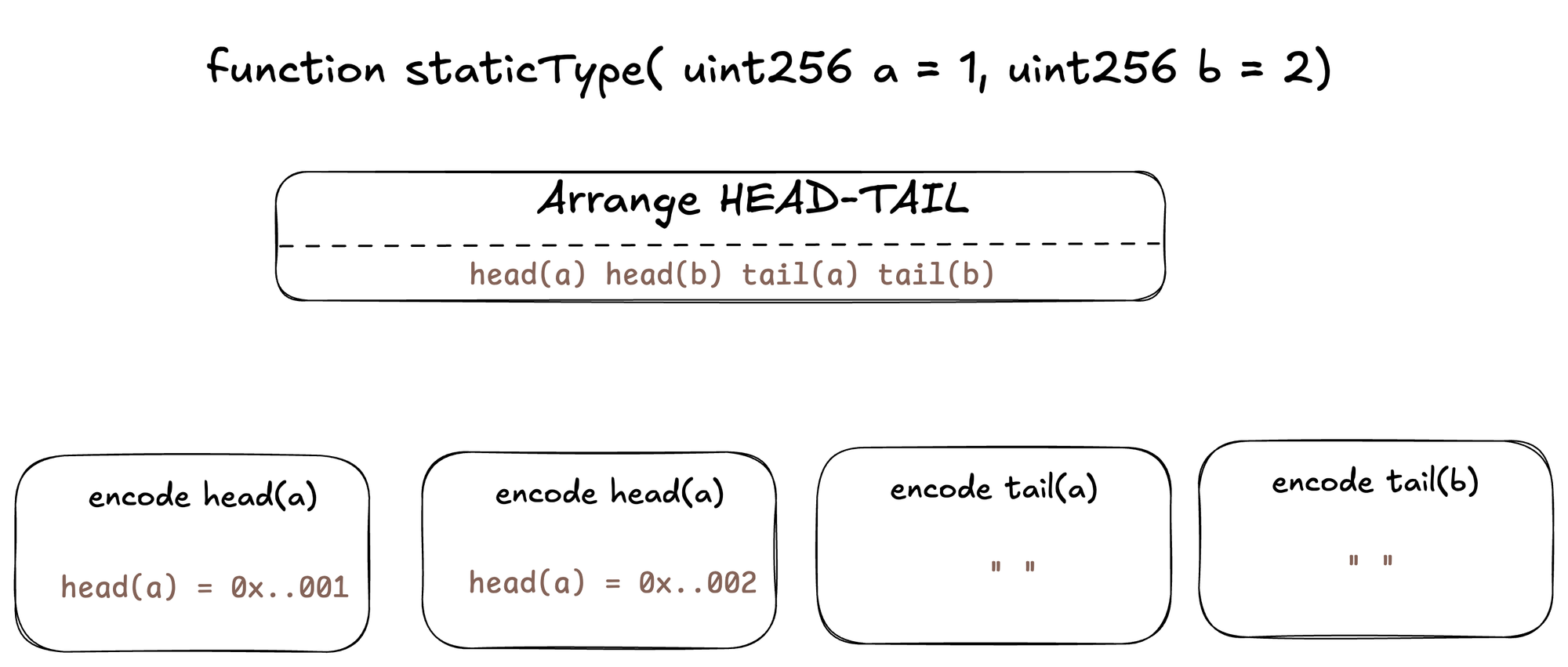
- notice how encoding of static types is as simple as the head itself contains the encoded values
- while the tail for static types are empty.
Calldata for dynamicType function:
Function-Selector: 46641647
------------
[000]: 0000000000000000000000000000000000000000000000000000000000000020
[020]: 000000000000000000000000000000000000000000000000000000000000000c
[040]: 4465636970686572436c75620000000000000000000000000000000000000000
Its visual representation can be seen as:
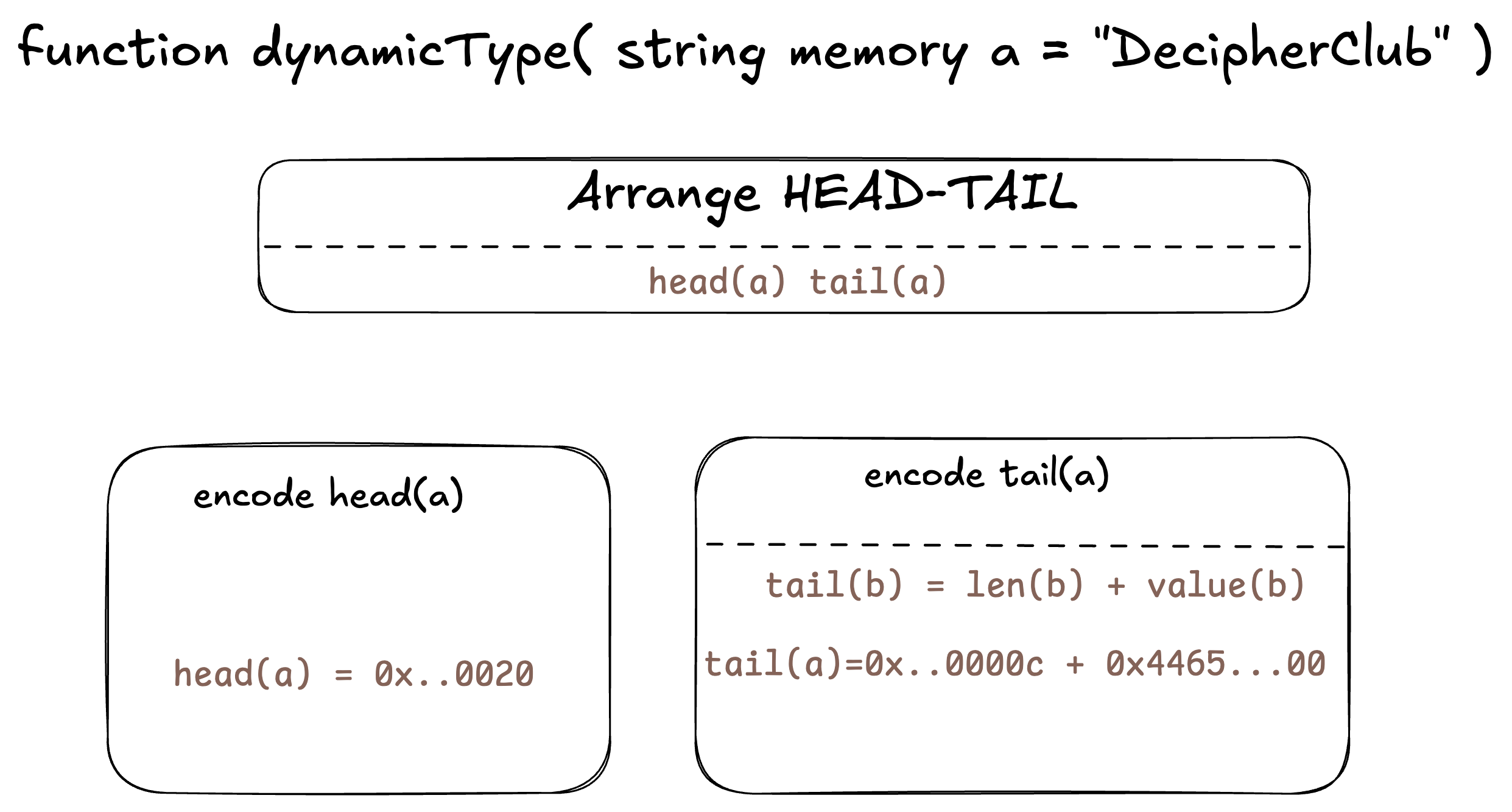
- The head includes 0x20, which is the pointer to where tail(a) is. ( check this in the calldata output above )
- while the tail contains the actual value, i.e., ( length + encoded value of string)
Note: This is only to show the head-tail arrangement. we will explore encoding mechanism in the next detailed examples
Now, our next task is to apply these rules and see if they work.
Pro Tip: The more you iterate with examples explained below, the better you understand how ABI encoding works.
Apply the Rules
You now have a theoretical understanding of all the concepts needed to understand how ABI Encoding works.
You also have a set of rules that will never change.
All we need to do now is apply those rules and verify that they work as expected.
We will apply the encoding rules to 3 different types of functions:
- function with only static type arguments
- functions with only dynamic type arguments
- functions with a mix of both types
To begin with, we will solely focus on static type to mainly understand the following:
- What does arranging function arguments in a tuple look like?
- What does arranging in heads and tails look like?
- What does encoding look like?
for now, don’t even worry about dynamic types.
It's about building muscle memory for how to analyze any function and arrive at the correct calldata using the same mental model every time.
Function with Static-Type only
Let’s start with a basic example of a function with only static type arguments:
// arguments ( a=1, b=2, c=3 )
function encodeFirst(uint256 a, uint256 b, uint256 c) public pure returns (bytes memory) {
return msg.data;
}
Step 1: Think in Tuples
Recall the first rule and group all the function arguments into a tuple with heads-tails formation.
Remember that solidity always considers all arguments as if they are one combined tuple.
So we think of the input like this:
This tuple has 3 elements: a, b, and c.
tuple(a, b, c)
// Forming it in heads-tail formation
encoded = [head(a)] [head(b)] [head(c)] [tail(a)] [tail(b)] [tail(c)]
Step 2: Visualize the Head–Tail Layout
Now, recall the universal rule for heads and tails of static type values:
Since all types are static:
- Each
head(x)= encoded value ofx(padded to 32 bytes) - Each
tail(x)= empty (because static types have no tail)
encoded = [head(a)] [head(b)] [head(c)] [tail(a)] [tail(b)] [tail(c)]
So it looks like this:
[ head(a) ] → 32 bytes of a
[ head(b) ] → 32 bytes of b
[ head(c) ] → 32 bytes of c
[ tail(a) ] → (empty)
[ tail(b) ] → (empty)
[ tail(c) ] → (empty)Even though the tails are empty, we still mentally place them to reinforce the structure — this is what will allow us to handle dynamic cases seamlessly later.
Step 4: Determine the argument type and Encode Each Value
We have 3 arguments, and all are of static type ( uint256 ).
Let’s now encode the arguments. In our case, the arguments are: ( a=1, b=2, c=3)
To encode, recall the rules of encoding for static types:
- all arguments are always encoded as 32-bytes
- head encoding of static type is the encoded value of the argument itself.
- Encoding follows big-endian layout (most significant bytes first) with padded on the left with zeros (i.e., right-aligned.
head(a): 0000000000000000000000000000000000000000000000000000000000000001
head(b): 0000000000000000000000000000000000000000000000000000000000000002
head(c): 0000000000000000000000000000000000000000000000000000000000000003
tail(a): "" // empty
tail(b): "" // empty
tail(c): "" // empty
Step 5: Combine HEADs and TAILs
We have now encoded the heads and tails of all arguments in this function.
If we combine all of them together, we should get the encoded value of all arguments that was sent to the contract.
Function Selector should be prepended:
We must not forget the function selector.
Every call to a function in Solidity starts with a 4-byte function selector.
To compute the function selector, you can use the cast CLI tool from foundry and run this command:
cast sig "encodeFirst(uint256,uint256,uint256)"
// This is basically keccak256("encodeFirst(uint256,uint256,uint256)")[:4]
// i.e., first 4 bytes of keccak256 hash of function signatureThis will return 0xb2bc9513 as the function selector for encodeFirst() function.
Now prepend the selector to the encoded arguments:
final calldata =
0xb2bc9513 // function selector
0000000000000000000000000000000000000000000000000000000000000001
0000000000000000000000000000000000000000000000000000000000000002
0000000000000000000000000000000000000000000000000000000000000003
Encoding static-type-only values are quite easy.
The real challenge begins with dynamic types. Let's take a simple string ( a dynamic type ) and apply our rules to see if we can encode correctly.
Another useful cast CLI command is: cast pretty-calldata <calldata>
this provides a readable prettified version of the calldata.
But First, Offsets...
Recall the rules again.
For Dynamic Types:
- The head holds a 32-byte offset, which points to the tail — i.e., the actual value.
For static values, we simply encoded the value itself and placed it in the head section. (while the tails were empty ).
It's different with dynamic values. The head must contain the offset/location that points to where the tail is.
But, how do we calculate the offset for a given dynamic value or set of dynamic values as function arguments?
Rules of Offset Calculation of Dynamic Type Values
When an argument is dynamic, its head must point to where its tail starts, and this value must be encoded as a uint256.
That offset is measured from the start of the entire argument encoding block (i.e., just after the 4-byte function selector), not from the beginning of the calldata.
For a dynamic argument at the position i:
- The head contains the offset to the start of its tail, which equals:
32 * number_of_arguments+total size of tails before the argument at position i
In other words:
- Count the size of the head section (always
32 × number of arguments) - Add up the total size of all previous tails (only the ones before this dynamic argument)
- The result is the offset to this argument’s tail, and that’s what goes into the head
Example Breakdown
For a function like:
function f(string a, string b)
or
encoded = [head(a)][head(b)][tail(a)][tail(b)]
head(a)= 0x40:- head(a) represents head for string a, which is the first argument. ( no tails before this argument.So)
- So, we only care about total argument values, i.e., 2. ( argument a and b )
- Following the rule: 32 * 2 gives us 64, which is 0x40 ( because the first tail starts after the two 32-byte heads, which together occupy 64 bytes. )
- Thus, head(a) is 0x40, meaning the tail ( actual value of string a can be found at position 0x40). Following
head(b)= 0x80- head(b) represents the head for string b, which is the second argument.
- The first 2 arguments (a and b) are dynamic types, so their heads occupy the first
32 * 2 = 64 bytes→ that’s 0x40 in hex. ( sotail(a)starts at offset 0x40, we already know this ) - Now, for argument b, we must consider the following first:
- 64 bytes taken by the heads of two arguments, a and b.
- space needed for
tail(a), i.e.:- a is a string type, which means it needs two 32-byte slots for storing its length and then its value.
- Total Space: 64 bytes + 32 bytes ( for
tail(a)) = 128 or 0x80 in hex
- So,
head(b)=0x80— meaning the actual valuestring bbegins at offset 128 bytes from the start of the argument block.
Let's take a look at the encoded values to see if the rule actually fits accurately.
Method: 0x18159cfb ← function selector for f(string,string)
------------
[000]: 0000000000000000000000000000000000000000000000000000000000000040 ← head(a): offset to tail(a), which starts at byte 0x40
[020]: 0000000000000000000000000000000000000000000000000000000000000080 ← head(b): offset to tail(b), which starts at byte 0x80
[040]: 000000000000000000000000000000000000000000000000000000000000000c ← tail(a) length: 12 bytes
[060]: 4465636970686572436c75620000000000000000000000000000000000000000 ← tail(a) data: UTF-8 encoded "DecipherClub", right-padded to 32 bytes
[080]: 000000000000000000000000000000000000000000000000000000000000000c ← tail(b) length: 12 bytes
[0a0]: 4465636970686572436c75620000000000000000000000000000000000000000 ← tail(b) data: UTF-8 encoded "DecipherClub", right-padded to 32 bytes
Now that you understand this, its time to play with encoding of dynamic-type arguments.
Function with Dynamic-Type Arguments only
We're now moving to functions with dynamic arguments, and this is where the head–tail model shines.
Let’s take this function:
// argument - s = "DecipherClub"
function encodeSecond(string memory s) public pure returns(bytes memory ){
return msg.data;
}
Step 1: Visualize the Head–Tail Layout
Let’s write out the logical structure using our standard model:
encoded = [head(s)] [tail(s)]
Because there's only one argument, its head goes first, then its tail.
Step 3: Determine Argument Type and Encode the Values
The argument s is of type string, which is a dynamic type in the ABI specification.
A dynamic type is any type whose size is not known at compile time. In this case, the length of the string "DecipherClub" can vary, so the compiler cannot determine its size ahead of time.Because it’s dynamic, its encoding will follow the head–tail structure:
- The head will store a pointer (an offset) to where the data begins
- The tail will store the actual content (length and data)
Now we’ll break this into two parts: encoding the head, and encoding the tail.
Step 3.a: Encoding the HEAD
As per the fundamental rules of ABI encoding, here’s what we know:
- Every argument — static or dynamic — is allocated exactly 32 bytes in the head section
- For dynamic types, the head does not store the actual value but an offset, which tells us how far from the start of the arguments the tail (i.e., actual value) begins
Therefore, your job now is to create that offset:
Recall the rule:
The offset is measured from the start of the argument encoding block, not from the start of the full calldata.
In this case:
- The head takes up the first 32 bytes
- There’s only one argument, so the tail starts right after the first 32 bytes
- Therefore, the offset is exactly
32 bytes = 0x20(in hex)
This value must itself be encoded as a uint256, which means we represent 0x20 as a 32-byte word with left-padding:
head(s) = 0x0000000000000000000000000000000000000000000000000000000000000020
So far, the ABI-encoded value looks like this:
[head(s)] → 0x0000000000000000000000000000000000000000000000000000000000000020
This tells the EVM:
"Hey, the actual data for s begins 32 bytes after the start of the arguments block."
Step 3.b: Encoding the TAIL
The tail for a dynamic type includes two components:
- The length of the data, in bytes
- The data itself, padded to the nearest 32-byte boundary
tail(s) = [length][value][padding]
Our job now is to create the tail for our given string value, i.e., “DecipherClub”
First, let’s get the length and encoded value:
- When we encode a
stringfor ABI purposes, Solidity first converts the string to a UTF-8 byte representation.
This is important because ABI doesn’t operate on letters or characters — it works on raw bytes. This ensures compatibility with off-chain tools like web3, ethers.js, and others that follow the same rules.
- Encoded Value: The UTF-8 value of “DecipherClub” is -
4465636970686572436C7562( verify here ). - Length of Value: There are 12 characters, so the UTF-8 byte length is
12, or in hex its0xc.
Thus, combining both of these value gives us the Tail:
tail(s) = [length][value][padding]
tail(s-length): 000000000000000000000000000000000000000000000000000000000000000c
tail(s-data) : 4465636970686572436c75620000000000000000000000000000000000000000Note on padding:
- The length field (
uint256) is padded with zeros on the left, making it 32 bytes. - The data field (UTF-8 bytes of the string) is right-padded with zeros so that the entire block is aligned to a 32-byte boundary.
Putting it all together:
Function Signature: 627a792c
------------
[000]: 0000000000000000000000000000000000000000000000000000000000000020 - head
[020]: 000000000000000000000000000000000000000000000000000000000000000c - tail
[040]: 4465636970686572436c75620000000000000000000000000000000000000000 - tailFunction with Mixed-Type Arguments ( static + dynamic )
Let’s try encoding functions with mixed arguments, i.e., both static and dynamic
function encodeThird(uint256 a, address b, string memory c) public pure returns (bytes memory) {
return msg.data;
}
arguments: (786, 0x5B38Da6a701c568545dCfcB03FcB875f56beddC4, "DecipherClub")
We have 3 arguments:
a:uint256(static)b:address(static)c:string(dynamic)
Step 1: Create a Tuple of Arguments
As always, start with creating the tuple
tuple(a, b, c)
encoded = [head(a)] [head(b)] [head(c)] [tail(a)] [tail(b)] [tail(c)]
// a and b are static , so they will not have any tails
encoded = [head(a)] [head(b)] [head(c)] [tail(c)]
Step 2: Determine Argument Types and Encode the Values
Let’s now go step-by-step and encode both the heads and tails separately.
Step 2.a: Encoding the HEADS
- Head of
a(uint256= 786)- Static type → head contains the value itself, padded to 32 bytes
- Hex value of
786=0x312
Head (left-padded):
head(a) = 0000000000000000000000000000000000000000000000000000000000000312- Head of
b(address=0x5B38Da6a701c568545dCfcB03FcB875f56beddC4)- Static type → head contains the value itself, padded to 32 bytes
addressis 20 bytes → padded with 12 zero bytes on the left\
head(b) = 0000000000000000000000005b38da6a701c568545dcfcb03fcb875f56beddc4
- Head of
c(string="DecipherClub")- Dynamic type → head must contain an offset
- There are 3 arguments, so the head section takes up 3 × 32 bytes = 96 bytes
- The tail for
cstarts right after the head section
Offset = 96 bytes = 0x60
Encode as a uint256 (left-padded):
head(c) = 000000000000000000000000000000000000000000000000000000000000006Final Head Section becomes:
// encoded value of 786 ( first argument )
[000]: 0000000000000000000000000000000000000000000000000000000000000312
// encoded value of address ( second argument )
[020]: 0000000000000000000000005b38da6a701c568545dcfcb03fcb875f56beddc4
// encoded value of offset for string "DecipherClub" ( offset 3rd argument )
[040]: 0000000000000000000000000000000000000000000000000000000000000060Step 3.b: Encoding the TAIL
We now encode the actual value of the string "DecipherClub". This is exactly similar to what we did previously.
- Get the length of the encoded string
- encoded value of “DecipherClub” -
0x4465636970686572436c7562 - Length -
12, or0xcin hex.
- encoded value of “DecipherClub” -
- Create the tail layout
tail(c) = [length][value][padding]
// Length is 0xc
000000000000000000000000000000000000000000000000000000000000000c
// Encoded value is
4465636970686572436c75620000000000000000000000000000000000000000Final Tail Section becomes
[060]: 000000000000000000000000000000000000000000000000000000000000000c
[080]: 4465636970686572436c75620000000000000000000000000000000000000000
Step 4: Combine Everything to Form ABI Encoded Payload
Now we combine:
[head(a)]
[head(b)]
[head(c)]
[tail(c)]
// Final Result
Function Signature: 0a4bef11
------------
[000]: 0000000000000000000000000000000000000000000000000000000000000312
[020]: 0000000000000000000000005b38da6a701c568545dcfcb03fcb875f56beddc4
[040]: 0000000000000000000000000000000000000000000000000000000000000060
[060]: 000000000000000000000000000000000000000000000000000000000000000c
[080]: 4465636970686572436c75620000000000000000000000000000000000000000
Visual Mental Model
Here is a visual mental model for encoding any given set arguments in a function using the rules explained above.
Consider a simple function with mixed-type arguments,:
function test( uint256 a, string b ) public {}
// arguments: a=2, b="DecipherClub"Now, to encode this function following the rules, we should follow this flow :
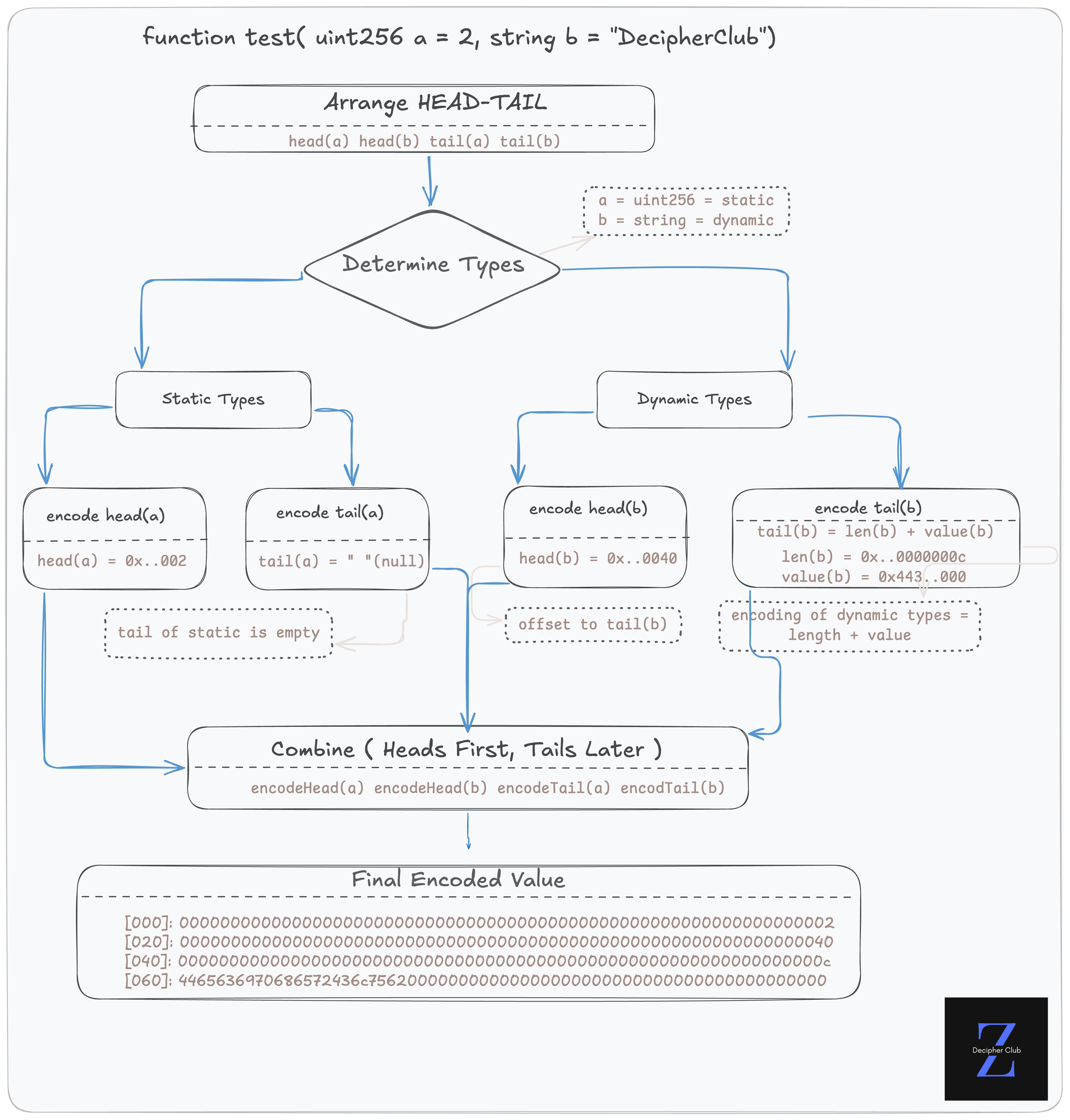
Wrapping it UP
In this first part of the series, we’ve dissected the ABI encoding process down to its finest bits and bytes. We also tried a mix of different types of encodings, including both types.
This should give you a strong mental model to understand the complete mechanics of ABI encoding. Read twice to understand better.
By now, you should feel comfortable reading an ABI-encoded payload byte by byte and understanding how the encoded data maps back to the original function and its parameters. Even better, you should be able to predict what the encoded output should look like before calling the function.
In the next part of this series, we’ll go even deeper, exploring advanced patterns like encoding of structs, arrays, nested and complicated dynamic types.
Cheers decipherers.
Special thanks to Owen Thurm ( Founder, Guardian Audits ),
Raoul ( Dev, Runtime Verification ), Abhimanyu ( co-founder, Epoch Protoocl ), Swayam ( Dev, Inco network), for their feedback and review.
Further Reading & References
- Mastering ABI Encoding for Solidity and Ethereum
- Understanding ABI encoding for function calls
- Mastering Calldata
- Contract ABI Specification
Got questions?
Join the community 👉 Decipher Club Telegram

![Why Learn Hard Solidity Things [ ABI Encoding Series: Part 0 ]](/content/images/size/w600/2025/06/ChatGPT-Image-Jun-8--2025--07_07_45-PM.png)